Audio & voice quality experience
MetricServer
Overview
Opale Systems MetricServer is an application that processes speech file pairs through industry standard algorithms such as POLQA® to determine indicators of voice quality and audio experience, including the Mean Opinion Score (MOS).
MetricServer targets Service Providers, Integrators and Mobile Carriers who need to monitor Voice services performances and Quality of Experience (QoE). This can be performed by postprocessing MOS and Voice Quality analysis on degraded speech files captured on any Test Systems.
an expert Voice Quality Analysis service in your test application
MetricServer provides the service layer for voice quality analysis and can be integrated into any proprietary test system thanks to its platform-independent Python API.
The reference and degraded speech files are passed from the third-party test application to MetricServer and the results are returned to the third-party test application, to a database or saved to a CSV file.
POOR QUALITY TROUBLESHOOTING
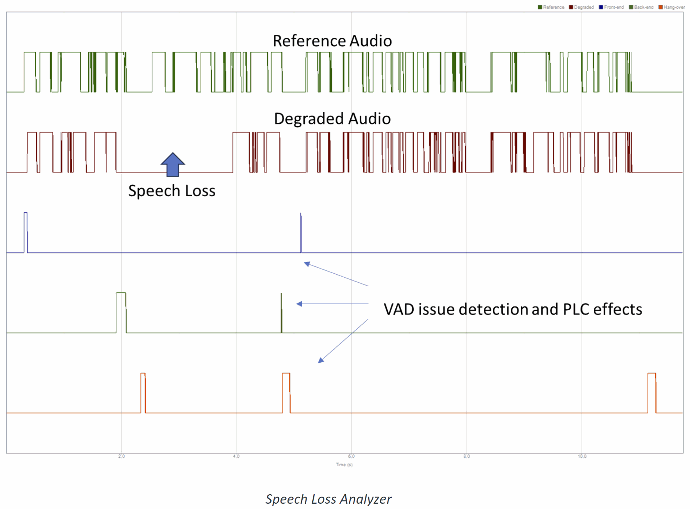
Thanks to the exclusive Speech Performance Analysis (SPA) feature, MetricServer enhances your ability to analyse poor MOS scores: MetricServer performs frame-by-frame speech and waveform analysis to provide detailed information such as frame-by-frame time offsets, frame-by-frame scores and speech loss analysis.
You can identify exactly which artefacts are causing your codec problems or what exactly led to the voice quality problem in the underlying system, and get a true sense of the user's perceived quality of experience.

 MetricServer (PDF File - 1.3 Mb)
MetricServer (PDF File - 1.3 Mb)





